Frodo Project
One designer. Nine AI agents.
A 24/7 autonomous office.
My role
- Systems architecture & orchestration
- Agent identity & behavior design
- LLM infrastructure & cost engineering
- Hardware/software integration
- Product design & full-stack engineering

About the project
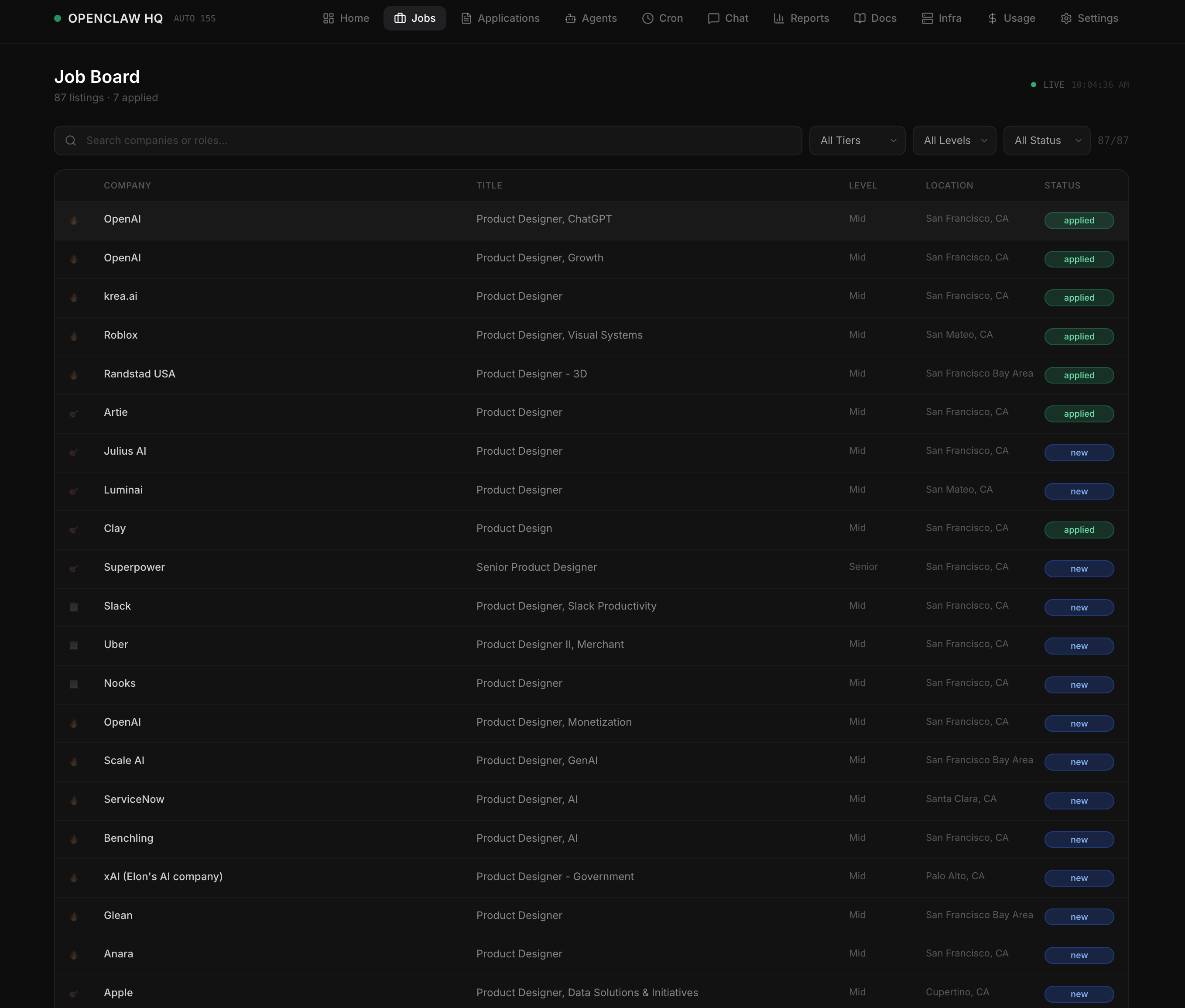
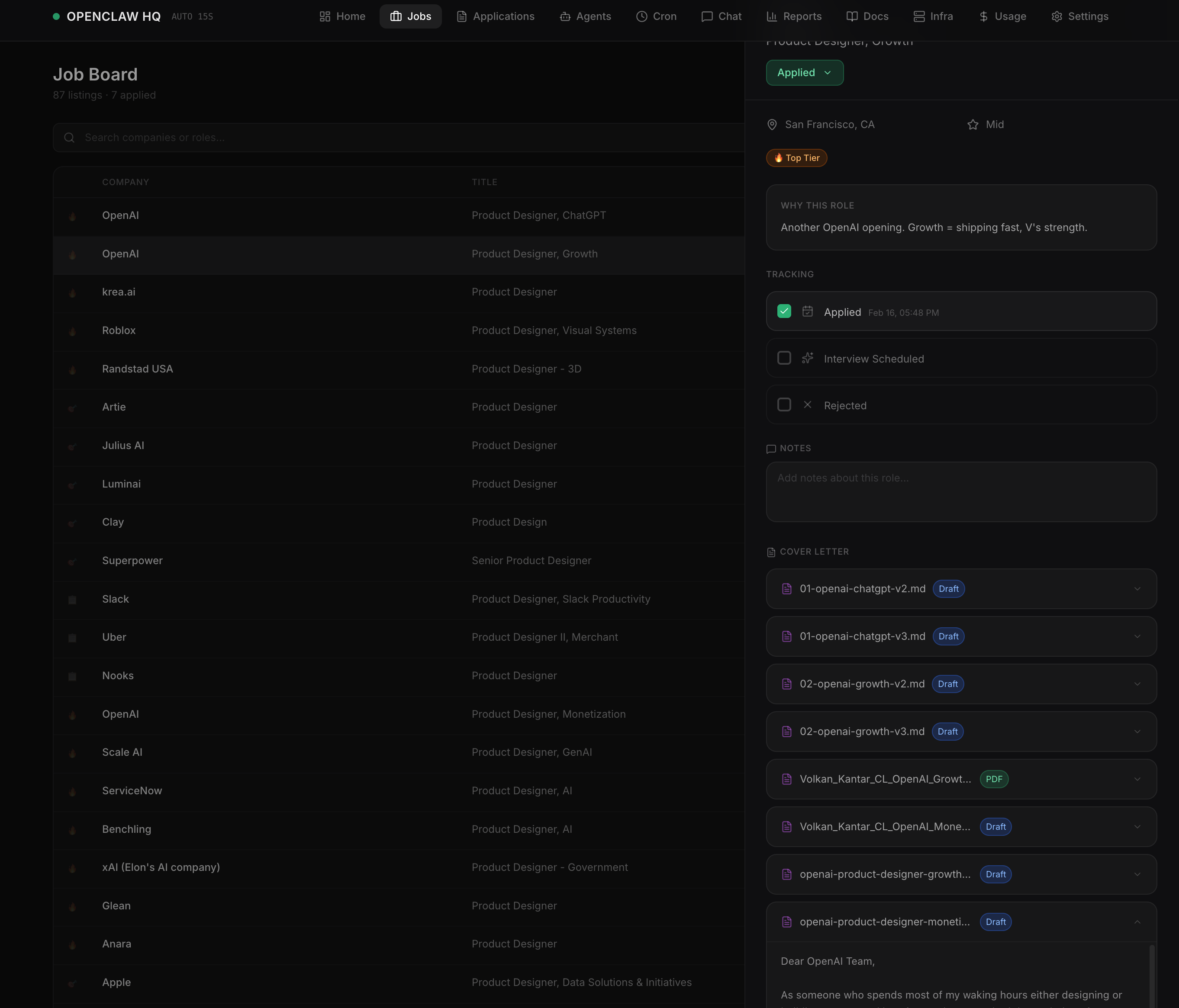
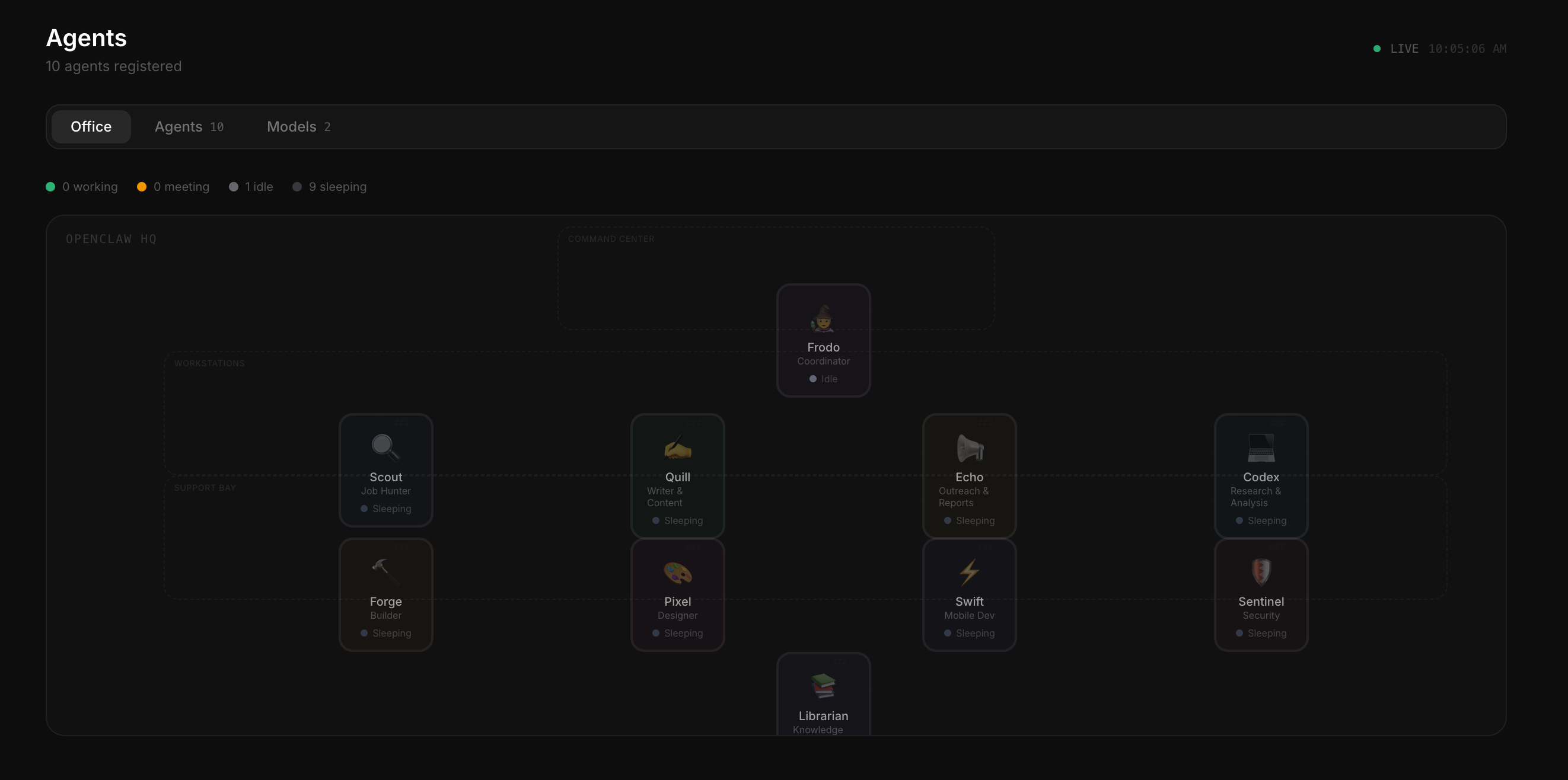
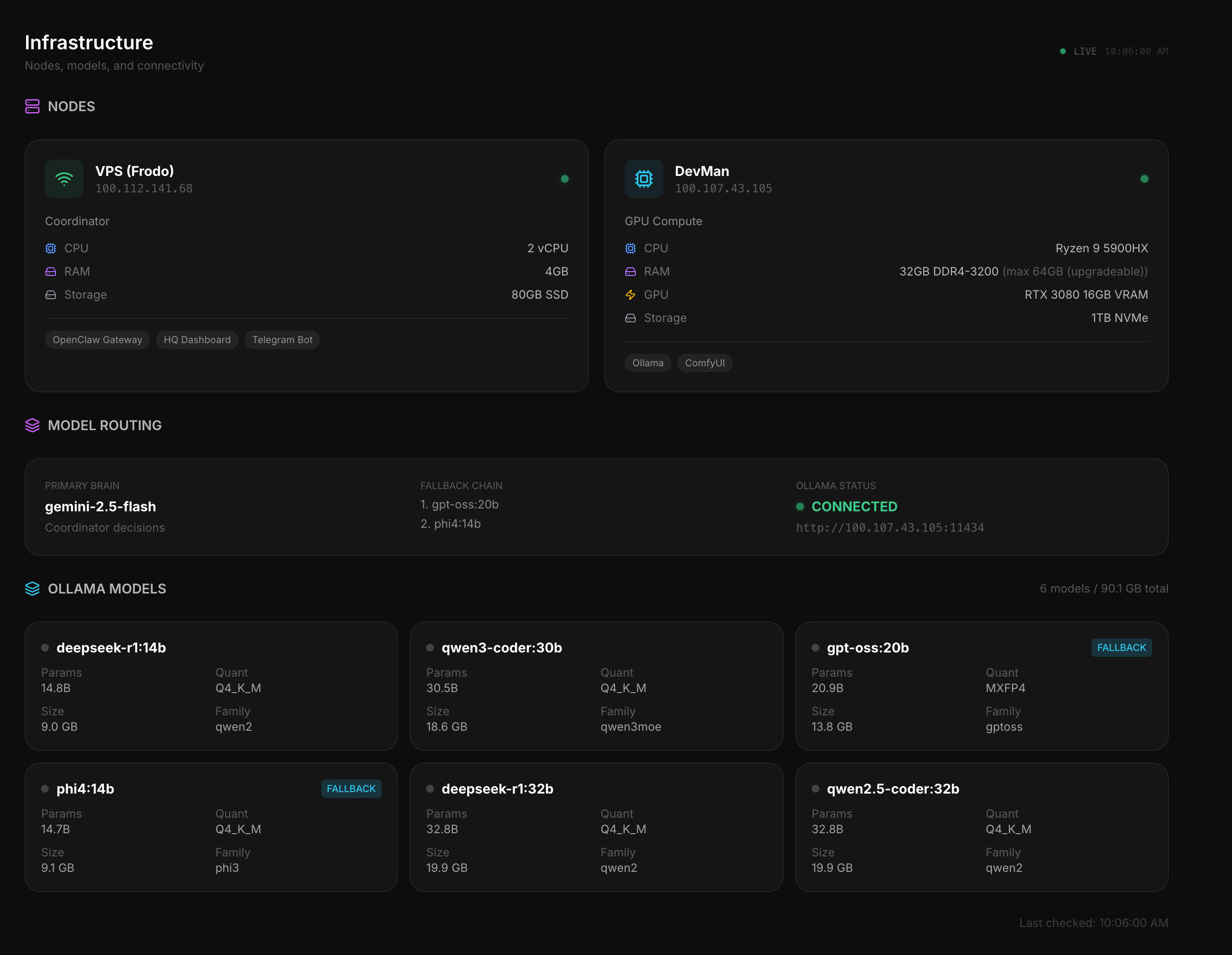
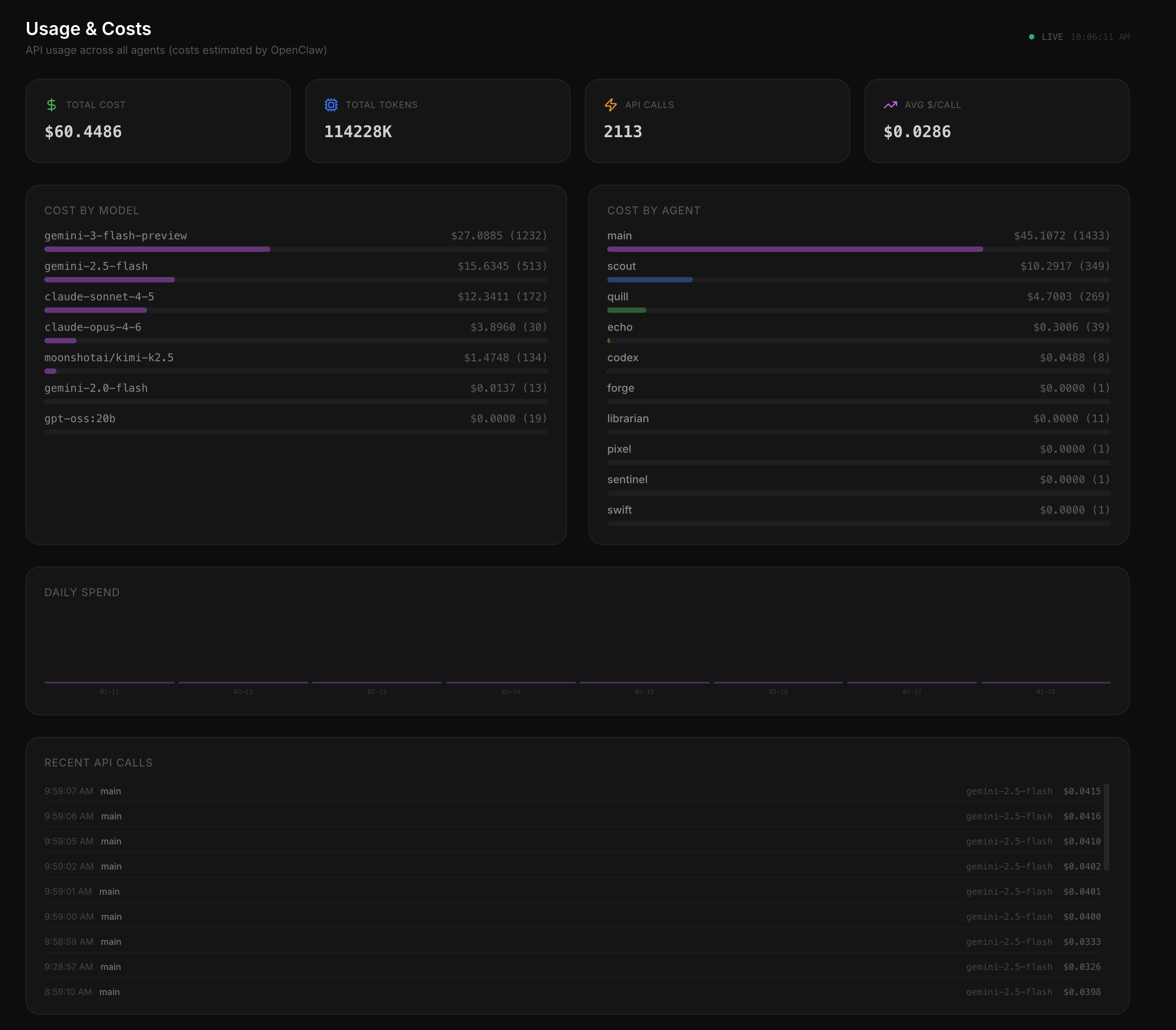
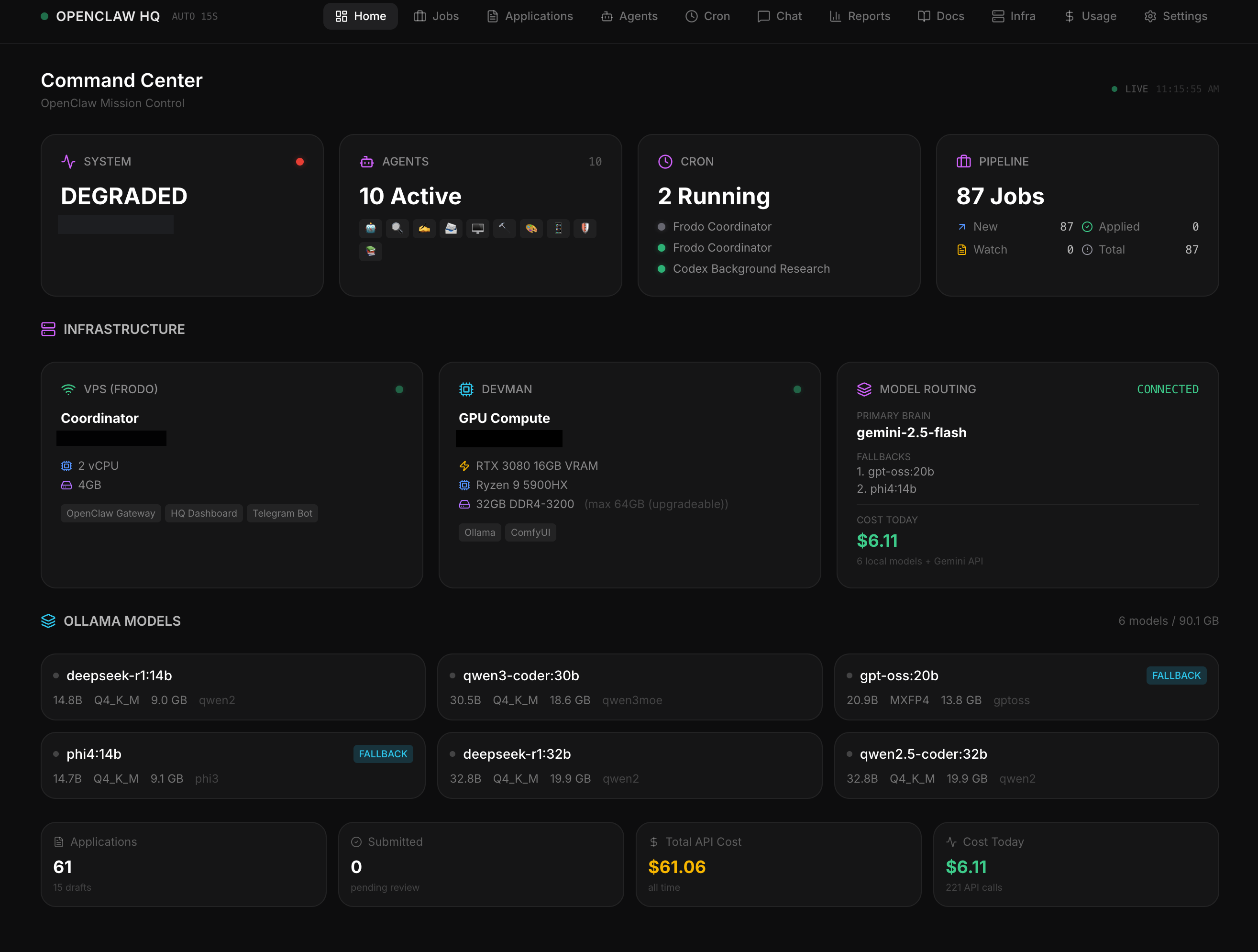
A fully autonomous multi-agent AI system: 9 specialized agents running 24/7 on real infrastructure. One paid coordinator brain, eight free local workers, connected across cloud and GPU hardware via VPN.
I applied the same principles I use to design product teams to orchestrate AI agents: clear roles, communication protocols, information hierarchy, and a single source of truth.
Built from scratch. Running in production. Not a demo.